[AWS SAA-C02 Study Note] Database Service: RDS, Aurora, Redshift, DynamoDB, DMS
RDS
Relational Database Service
A managed relational database service.v Support multiple SQL engines, easy to scale, backup and secure.
RDS is the AWS Solution for relational databases. There are 6 relational database options currently available on AWS.

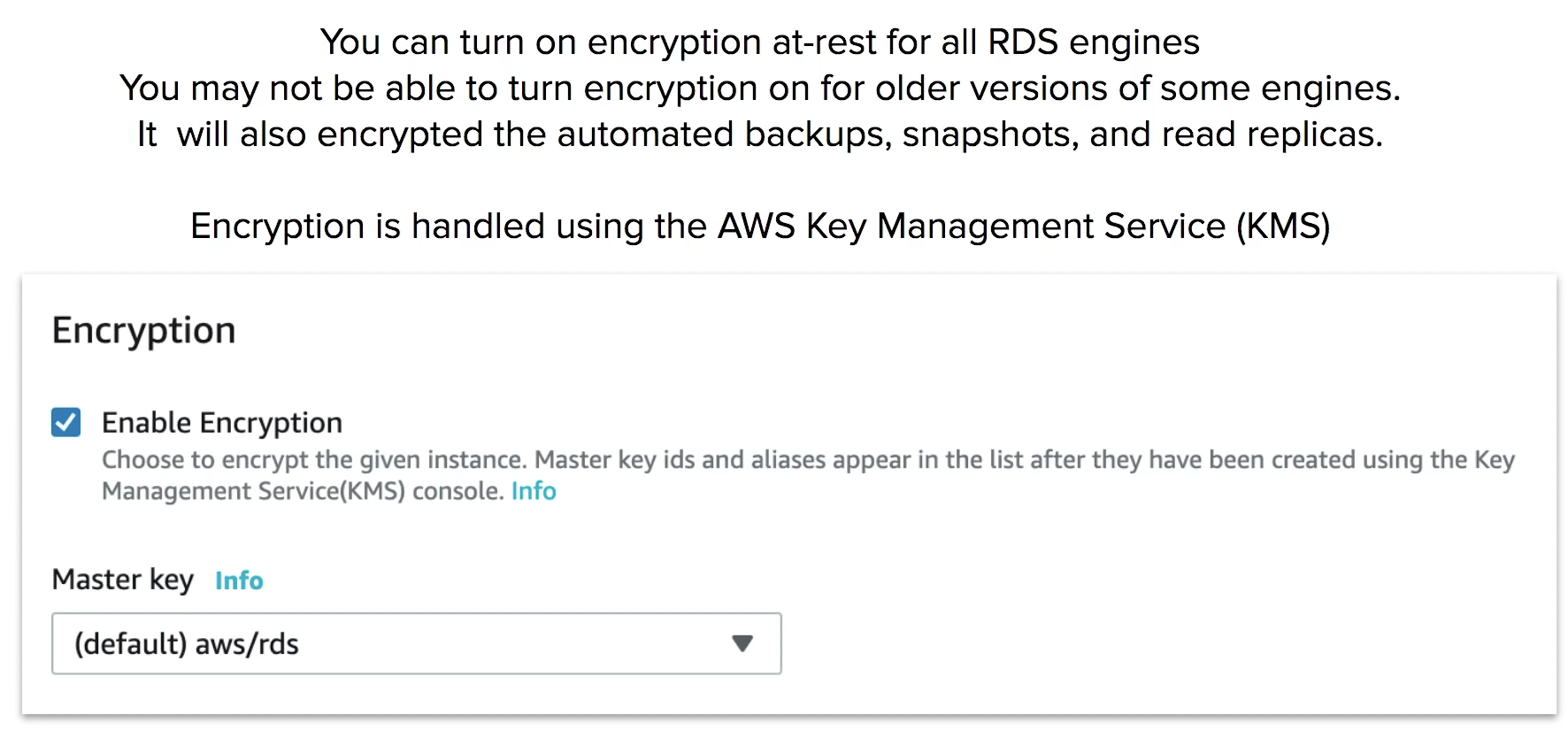
Encryption
Backup
There are two backup solutions available for RDS
- Automated Backups

- Manual Snapshots

Restoring Backup
When recovering AWS will take the most recent daily backup, and apply transaction log data relevant to that day. This allows point-in-time recovery down to a second inside the retention period.

Multi-AZ
ensure database remains available if another AZ becomes unavailable
Synchronize
makes an exact copy of your database in another AZ. Automatically synchronizes changes in the database over to the standby copy.
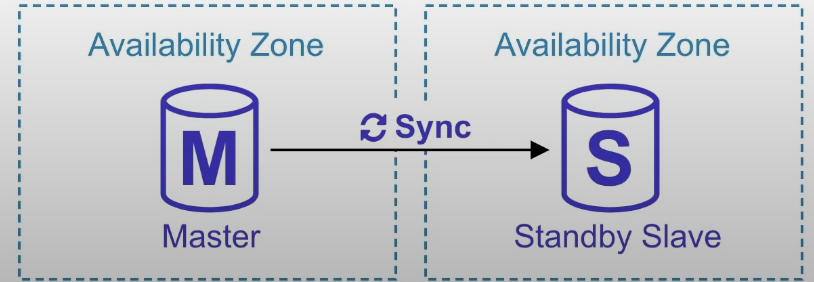
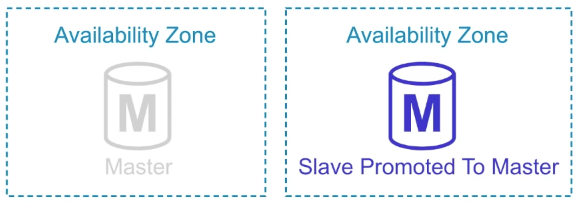
Automatic Failover Protection
If one AZ goes down, failover will occur and the standby slave will be promoted to master
Read Replicas
Read Replicas allow you to run multiples copies of your db, these copies only allows reads (no writes) and is intended to alleviate the workload of your primary db to improve performance.
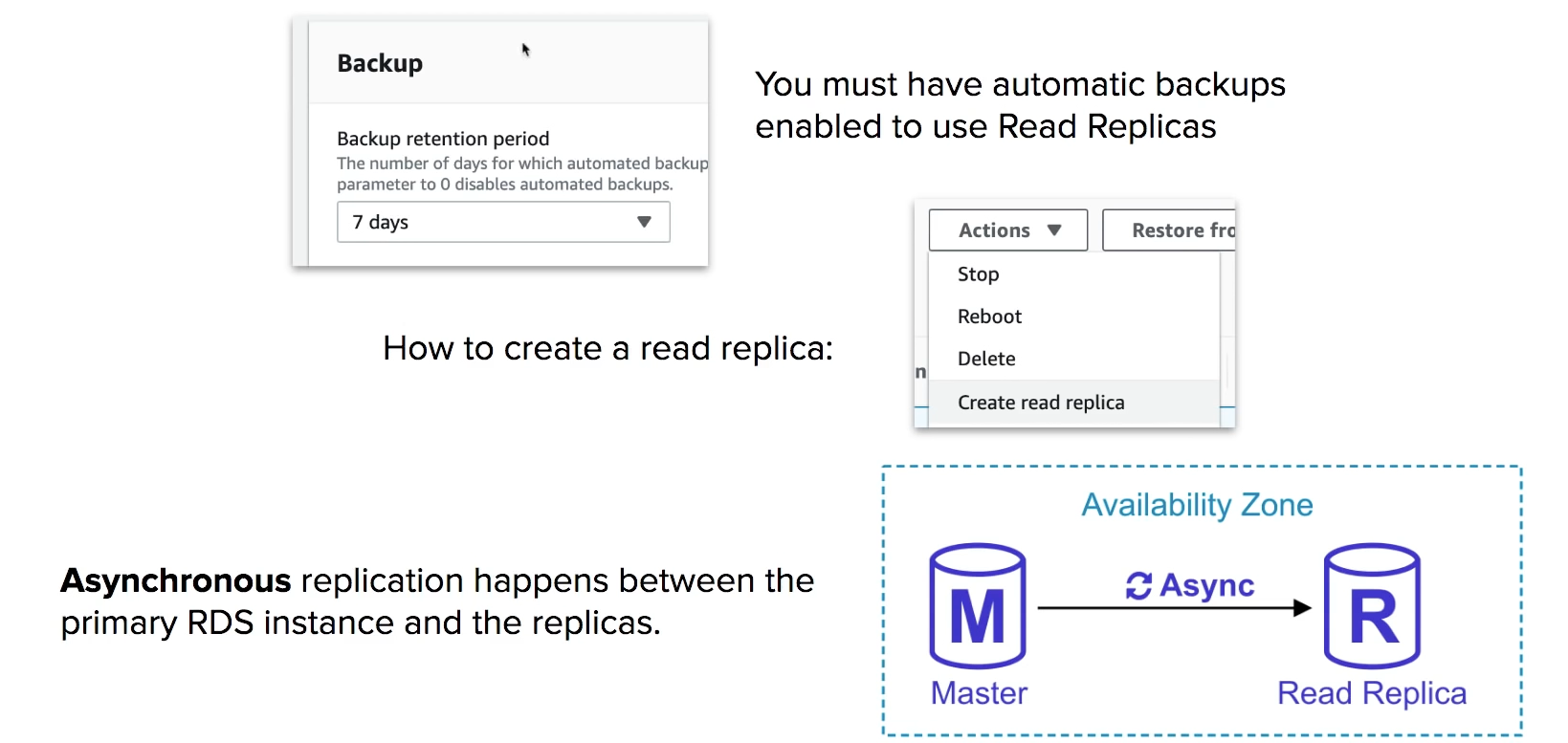
you can have up to 5 replicas of a database
each RR will have its own DNS endpoint
you can have Multi-AZ replicas, replicas in another region or even replicas of other replicas
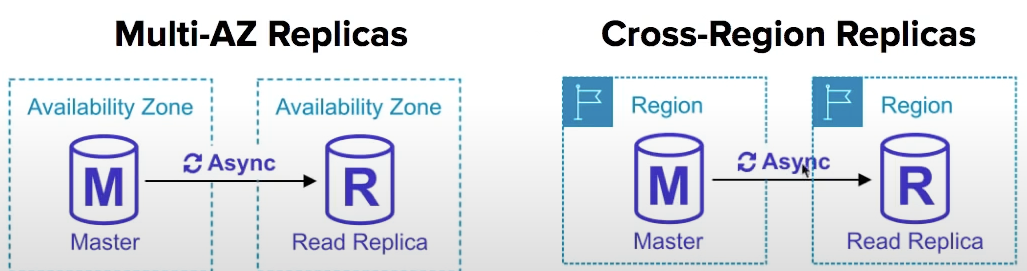
Replicas can be promoted to their own db, but this breaks replication.
No automatic failover, if primary copy fails, you must manually update urls to point at copy.
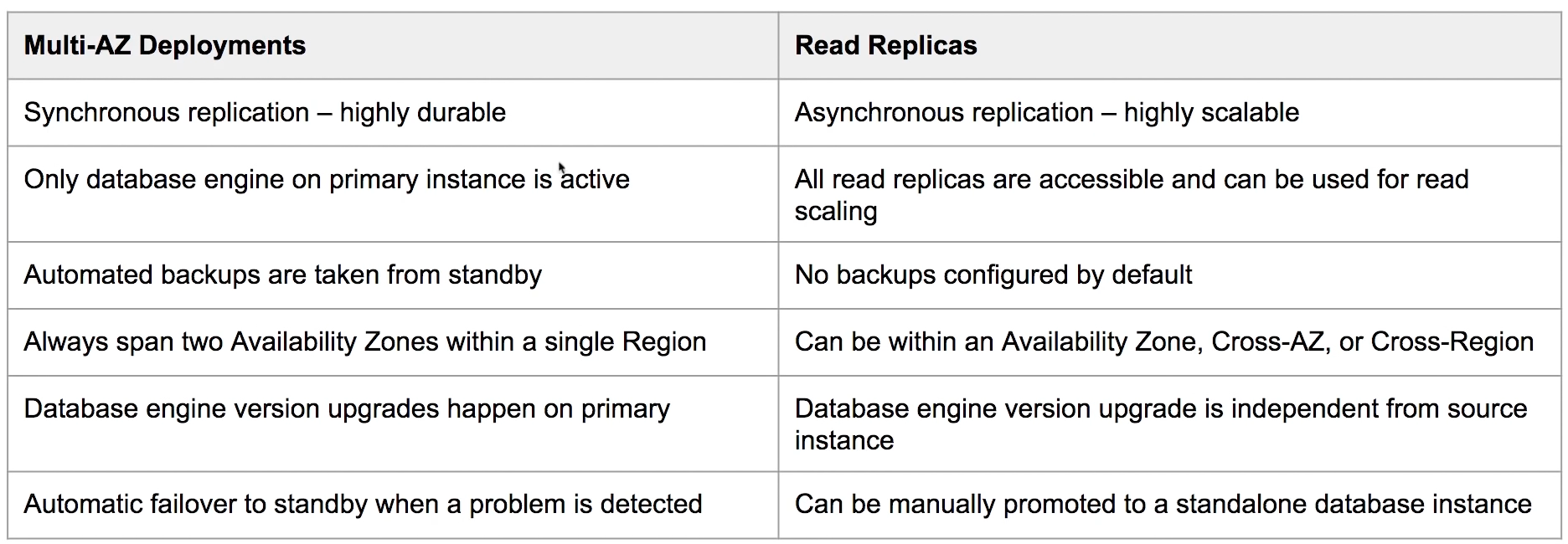
Multi-AZ vs. Read Replicas
RDS Cheat Sheet

Aurora
Fully Managed Postgres or MySQL compatible database designed by default to scale and fine-tuned to be really fast.
Intro to Aurora
combines the speed and availability of high-end db with simplicity and cost-effectiveness of open source db.

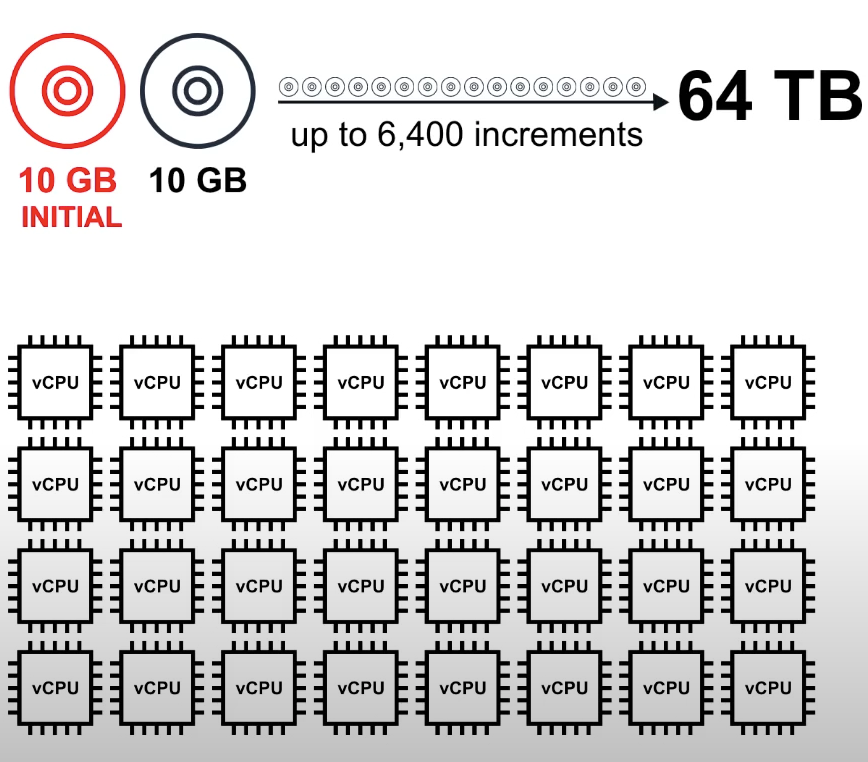
Scaling with Aurora
start with 10GB storage and scale in 10GB increments up to 64TB
storage is autoscaling
computing resources can scale all the way up to 32 vCPUs and 244GB of memory
Availability with Aurora
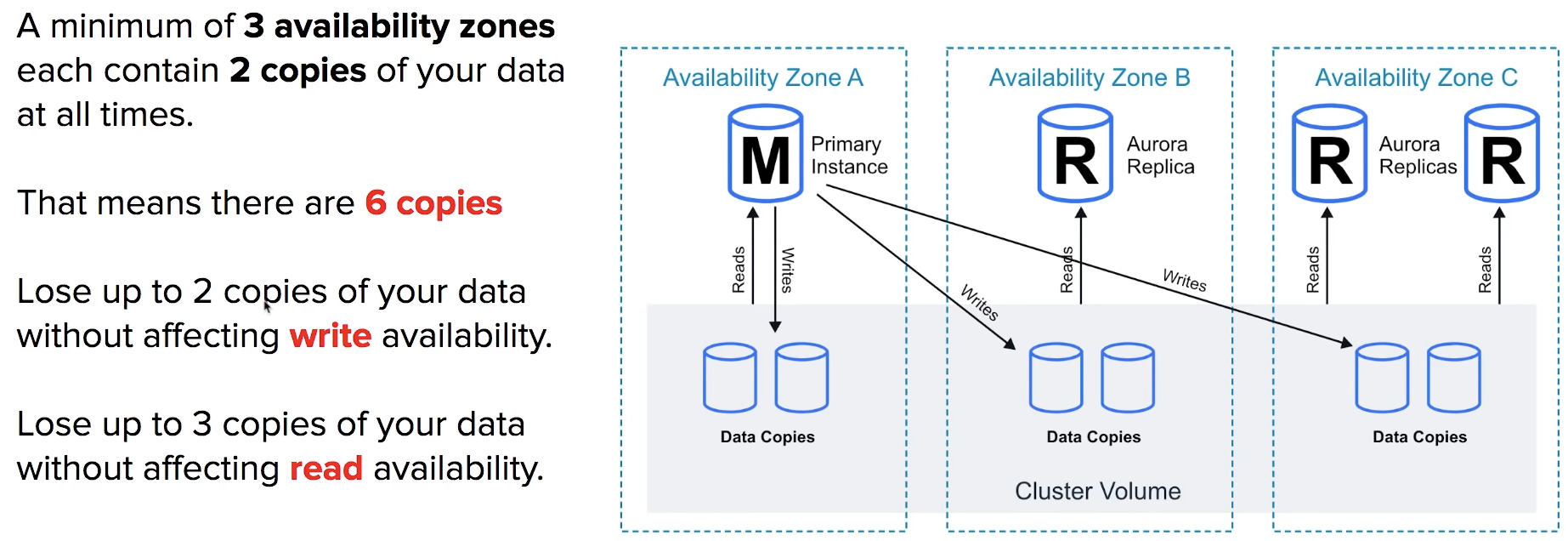
Fault Tolerance and Durabillity
Back-up and Failover is handled automatically

storage is self-healing, in that data blocks and disks are continuously scanned for errors and repaired automatically.
Aurora Replicas
2 types of replicas available
Up to 15 replicas

Aurora Serverless
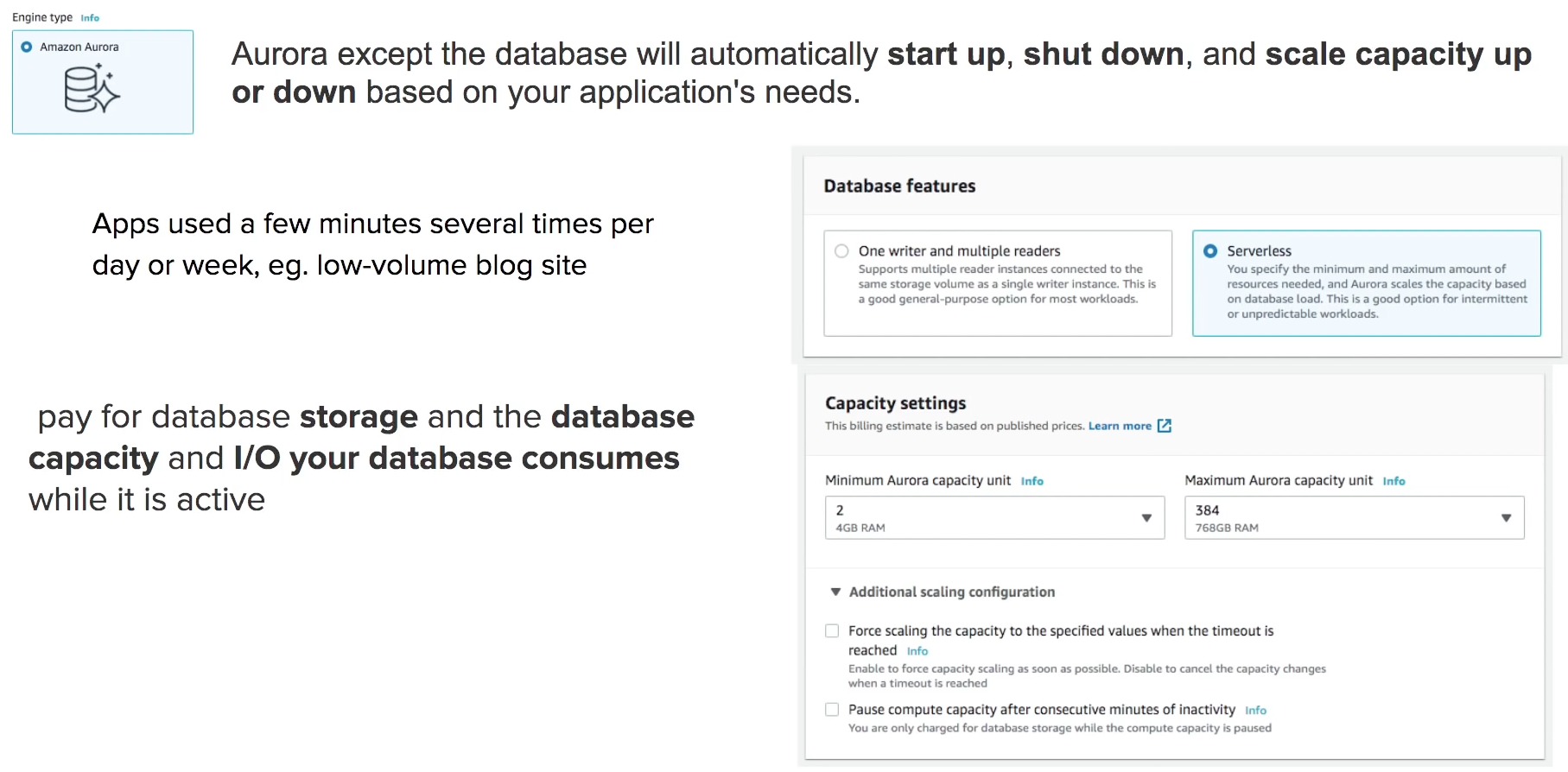
serverless is more elastic
compare to one writer and multiple readers, serverless is less expensive
Aurora Cheat Sheet

Redshift
Fully managed PB-size Data Warehouse
Analyze (Run complex SQL queries) on massive amounts of data Columnar Store Database.
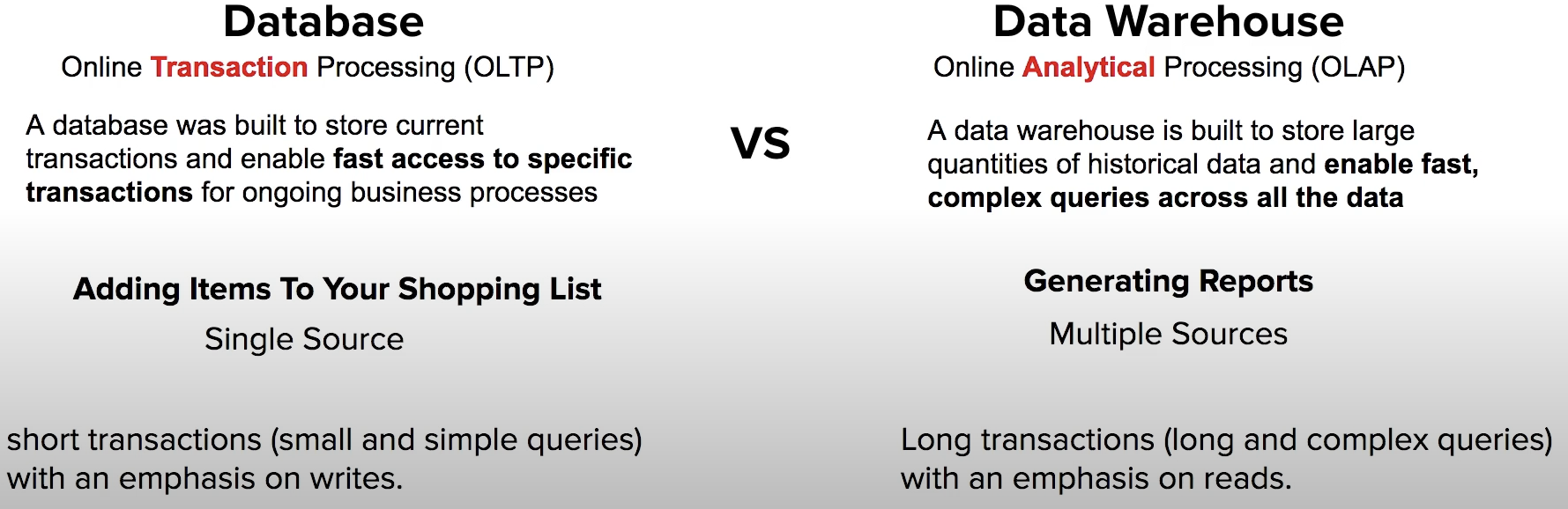
What is Data Warehouse?
what is database transcation?
A transaction symbolizes a unit of work performed within a database management system
ex. read and write
Intro of Redshift
less cost
use for Business Intelligence
OLAP

Use Case
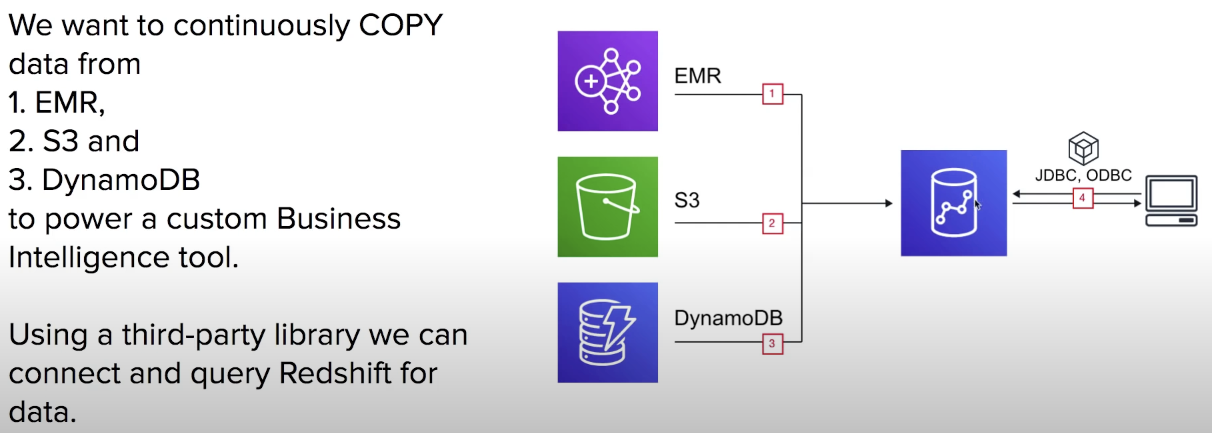
different source
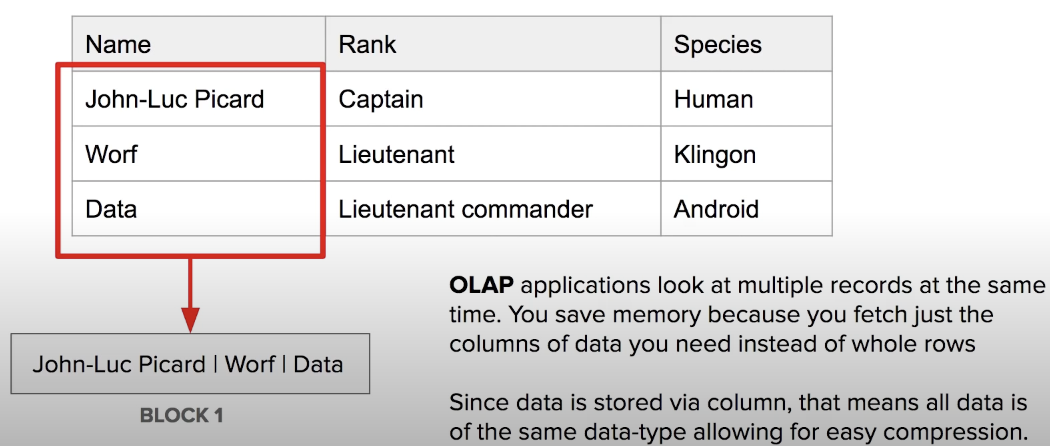
Columnar Storage stores data together as columns instead of rows
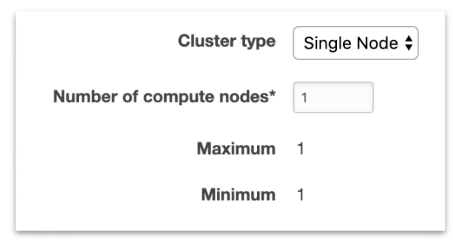
Configuration
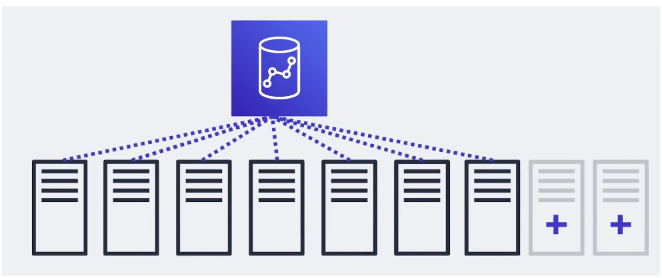
Single Node
Node come in size of 160GB. You can launch a single node to get started with Redshift.
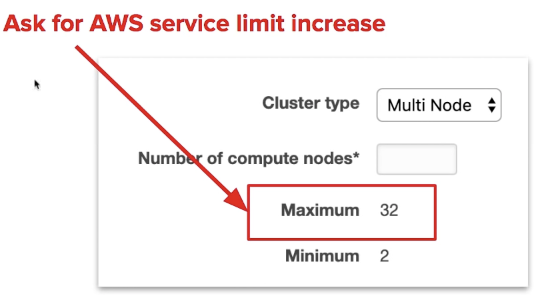
Multi-Node
you can launch a cluster of nodes with Multi-Node mode
- Leader Node: manage client connections and receiving queries
- Compute Node: store data and performs queries up to 128 compute node
Node Type and Sizes
There are two types of Nodes

Compression

Processing
Massively Parallel Processing (MPP)
Automatically distributes data and query loads across all nodes
Lets you easily add new nodes to your data warehouse while still maintaining fast query performance
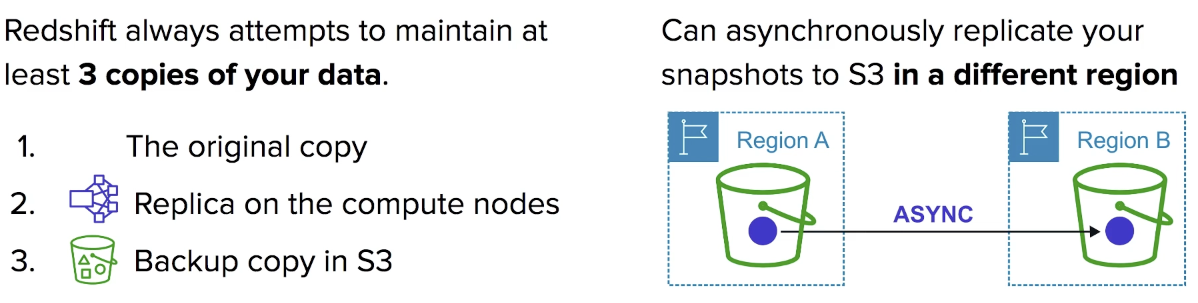
Back-up
backups are enabled by default with a 1 day retention period.
retention period can be modified up to 35 days.
Billing

Security
Data-in-transit: Encrypted using SSL
Data-at-rest: Encrypted using AES-256 encryption
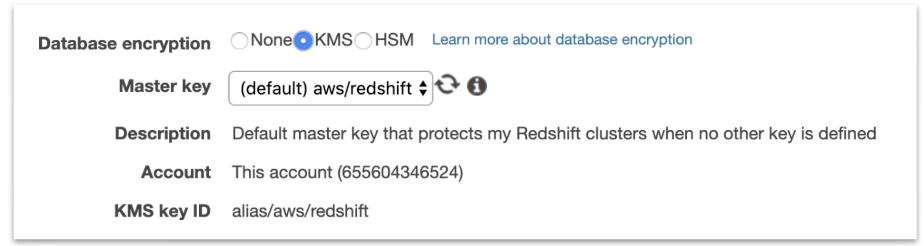
Database Encryption can be applied using
- KMS multi-tenant HSM
- CloudHSM single-tenant HSM
Availability
RS is a single AZ.
To run in Multi-AZ you would have to run multiple RS Clusters in different AZs with same inputs.
Snapshots can be restored to a different AZ in the event an outage occurs.

[Supplement] EMR
Amazon EMR is the industry-leading cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto.
Amazon EMR makes it easy to set up, operate, and scale your big data environments by automating time-consuming tasks like provisioning capacity and tuning clusters. With EMR you can run PB-scale analysis at less than half of the cost of traditional on-premises solutions and over 3x faster than standard Apache Spark.
You can run workloads on Amazon EC2 instances, on Amazon Elastic Kubernetes Service (EKS) clusters, or on-premises using EMR on AWS Outposts.
Redshift CheatSheet

DynamoDB
A key-value and document database (NoSQL) which can guarantees consistent reads and writes at any scale.
Intro to DynamoDB

define your read and write capacity

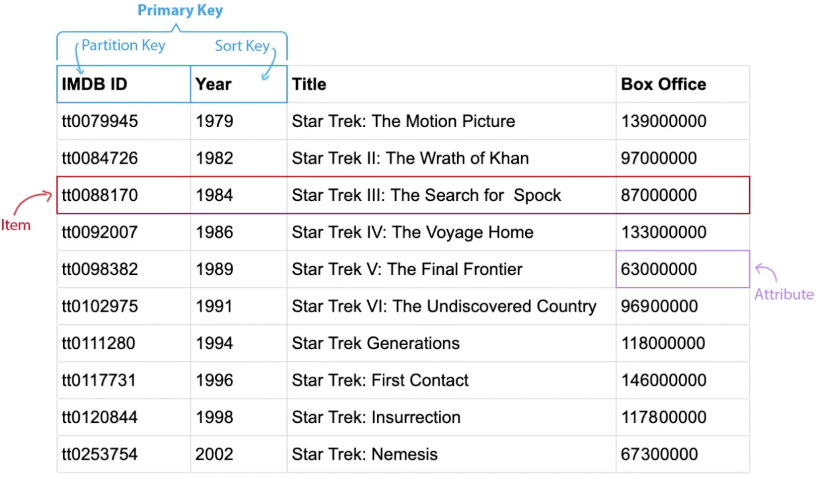
Table Structure
Consistent Read
When data needs to update it has to write update to all copies. It is possible for data to be inconsistent if you are reading from a copy which has yet to be updated. You have the ability to choose the read consistency in DynamoDB to meet your need.


DynamoDB Accelerator (DAX)
Amazon DynamoDB Accelerator (DAX) is a fully managed, highly available, in-memory cache for Amazon DynamoDB that delivers up to a 10 times performance improvement—from milliseconds to microseconds—even at millions of requests per second.
DAX does all the heavy lifting required to add in-memory acceleration to your DynamoDB tables, without requiring developers to manage cache invalidation, data population, or cluster management.
DynamoDB CheatSheet

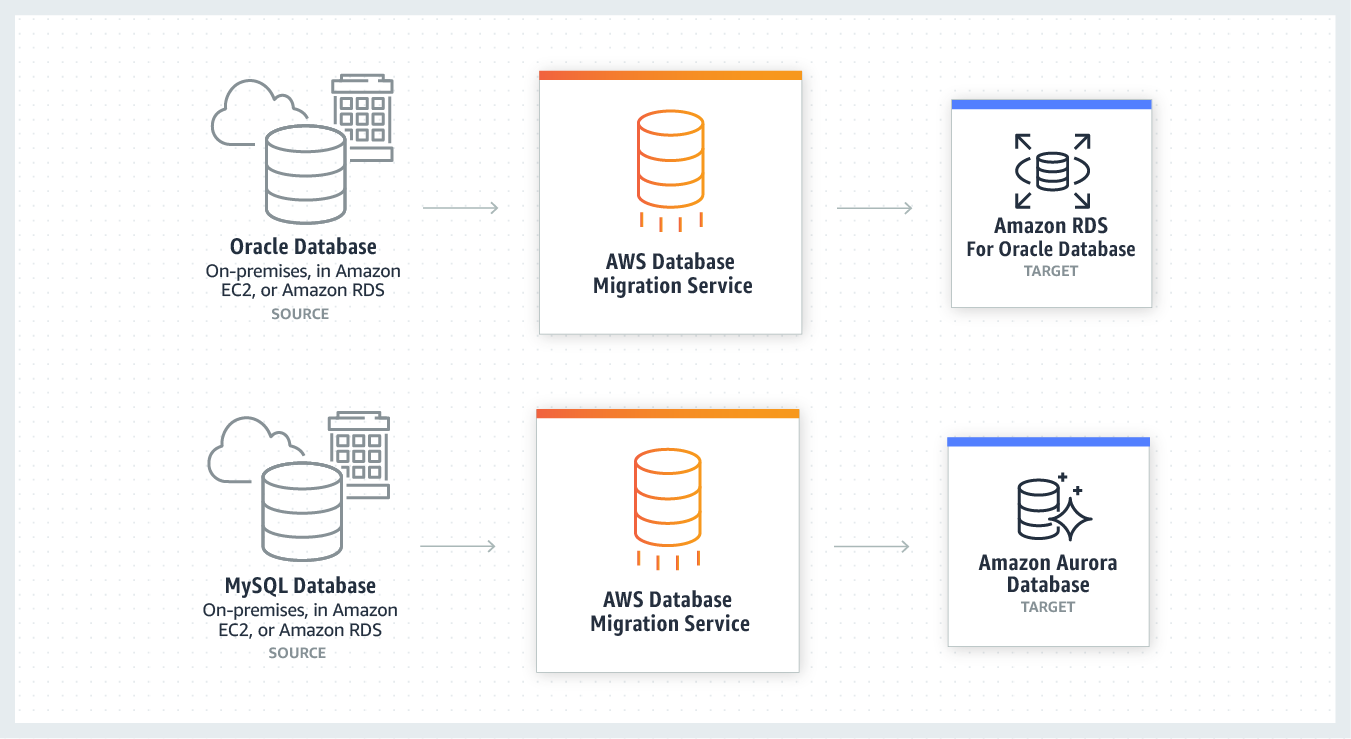
DMS
Database Migration Service
AWS Database Migration Service helps you migrate databases to AWS quickly and securely. The source database remains fully operational during the migration, minimizing downtime to applications that rely on the database. The AWS Database Migration Service can migrate your data to and from most widely used commercial and open-source databases.