GCP Associate Cloud Engineer Prepara Note
Cloud IAM
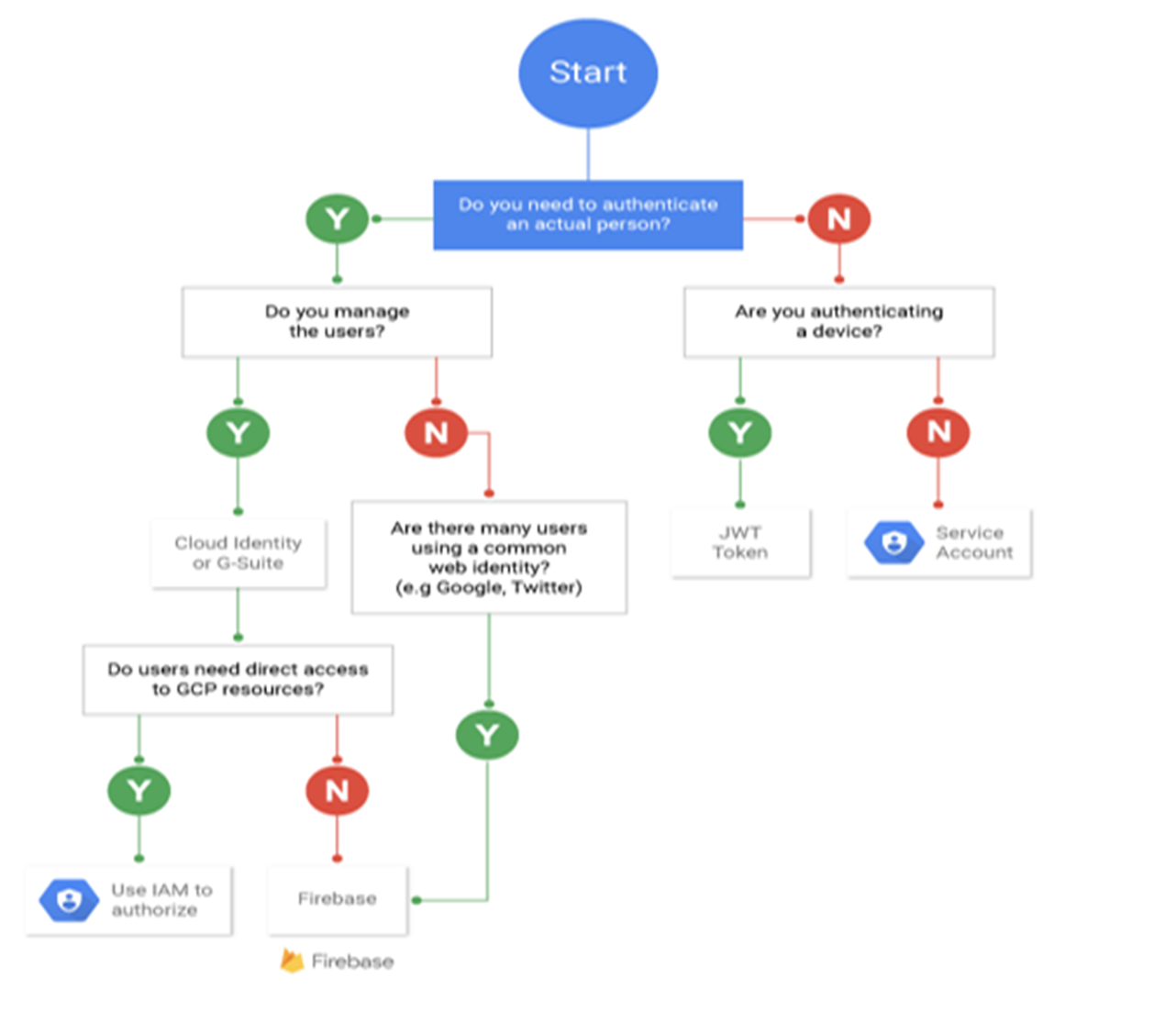
Identity and Access Management documentation | IAM Documentation | Google Cloud
IAM: Provides granular access to resources, prevents unwanted access to other resources and adopts the security principle of least privilege.
Core Components
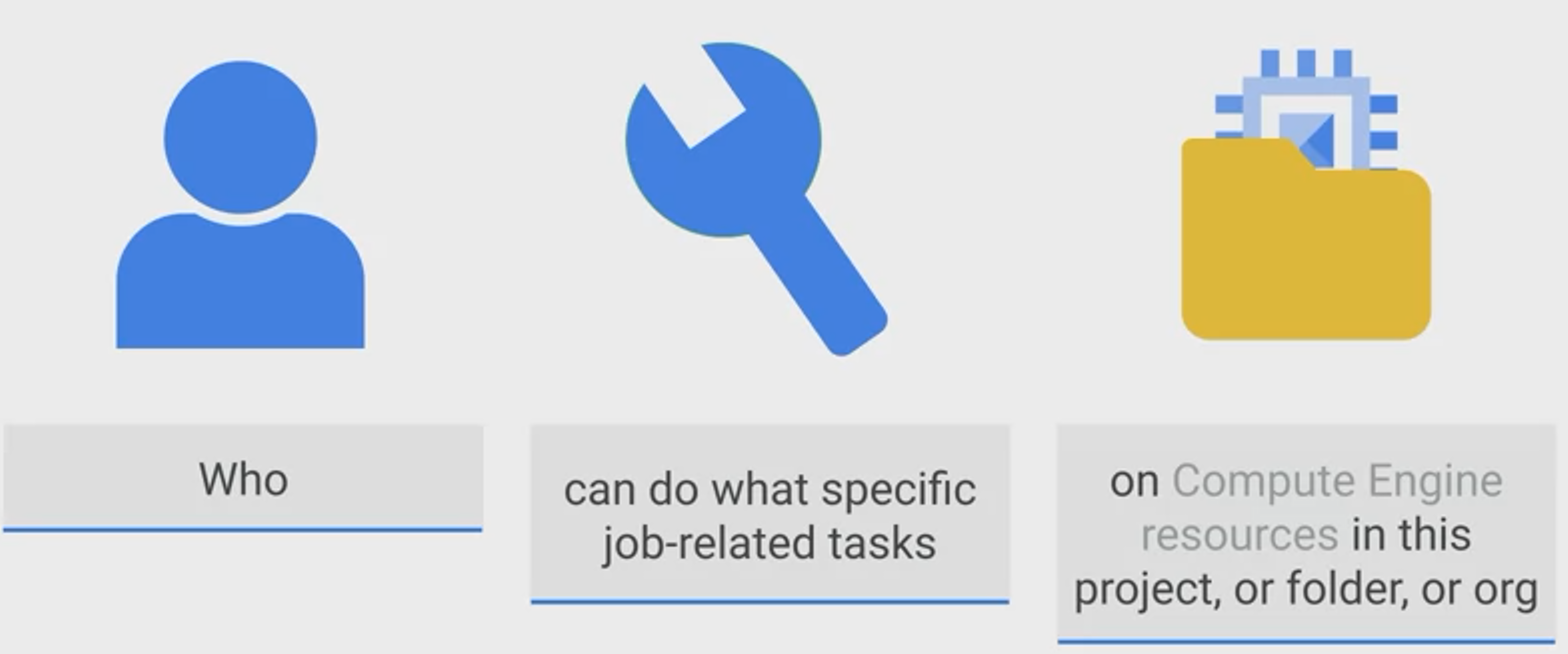
Members (Who)
Person (Google Account)
Google Group → image group of account
Service Account
Special type of account belonging to your application and can be identified by
<project_number/id>@developer.gserviceaccount.com→ for application
Permissions & Roles (What)
Role
- Collection of permissions to use or manage GCP resources
- Assigned to users
Permissions

Give access to a given resource
Identified by
<service>.<resource>.<verb>E.g.
pubsub.subscriptions.consume
Resources
Check reousrce Hierarchy
Policies
Bind Members to Roles at a hierarchy level
Such as Organisation, Folder, Project or Resource
Collection of Roles that define who has what type of access
Are hierarchally defined, with parent overruling child policy
Service Account
- Global
- Similar to AWS Role
- This is a special type of Google account that represents an application, not an end user
- Can be “assumed” by applications or individual users when authorised
Service Account Keys
- GCP-managed keys
- Keys used by GCP services such as App Engince and Compute Engine
- Key cannot be downloads
- Rotated automatically on a weekly basis
- User-managed keys
- Keys are created, downloadable, and managed by users
- Expire 10 years from creation
Primitive, Predefined & Customer Role
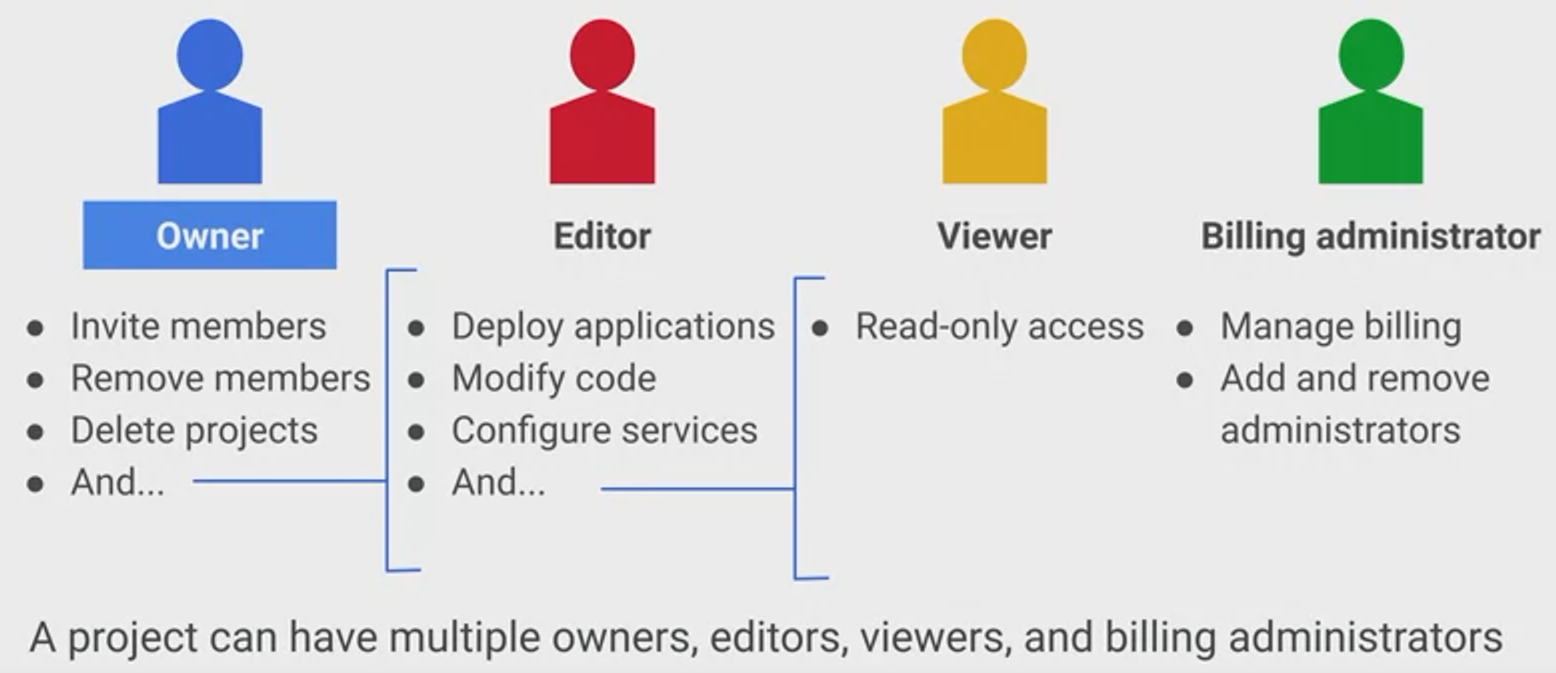
Basic roles are very coarse
Primitive (Basic)
Scope: Project, Folder
Historical roles before Cloud IAM was implemented.
Types:
- Viewer
- Read only
- Editor
- Read + Write
- Owner
- Read + Write
- Manage access to Project and resources
- Setup project billing
- Viewer
Predefined
predefined roles are fine-grained permissions on particular services
Scope: resource
Much more granular access, they are applied at the Resource level
Example:

Customer
Scope: organization, project
You can include many, but not all, IAM permissions in custom roles. Each permission has one of the following support levels for use in custom role
Group

Network
DNS
Google Domains
→ Like AWS Route53
Range: Global
- Google’s registrar for domain names
- Built-in DNS or custom nameservers
- Supports DNSSEC
Cloud DNS
Range: Global
- DNS service
- 100% uptime guarantee
- Low latency globally
- Supports DNSSEC
- Pay for:
- Hosted zone, fixed fee
- DNS lookups (i.e. usage)
Static IP
- Two types:
- Regional Static IP
- GCE Instances
- Network Load Balancers
- Global Static IP (Anycast IP)
- Global Load Balancers
- HTTP(S)
- SSL Proxy
- TCP Proxy Note:
- Global Load Balancers
- Regional Static IP
- Pay for IPs that are not in use
Cloud Load Balancing (CLB)
Range: Regional/Global
Built into their Software Defined Networking (SDN) system that can naturally handle spikes without any pre-warming
External vs. Internal

Global vs. Regional:
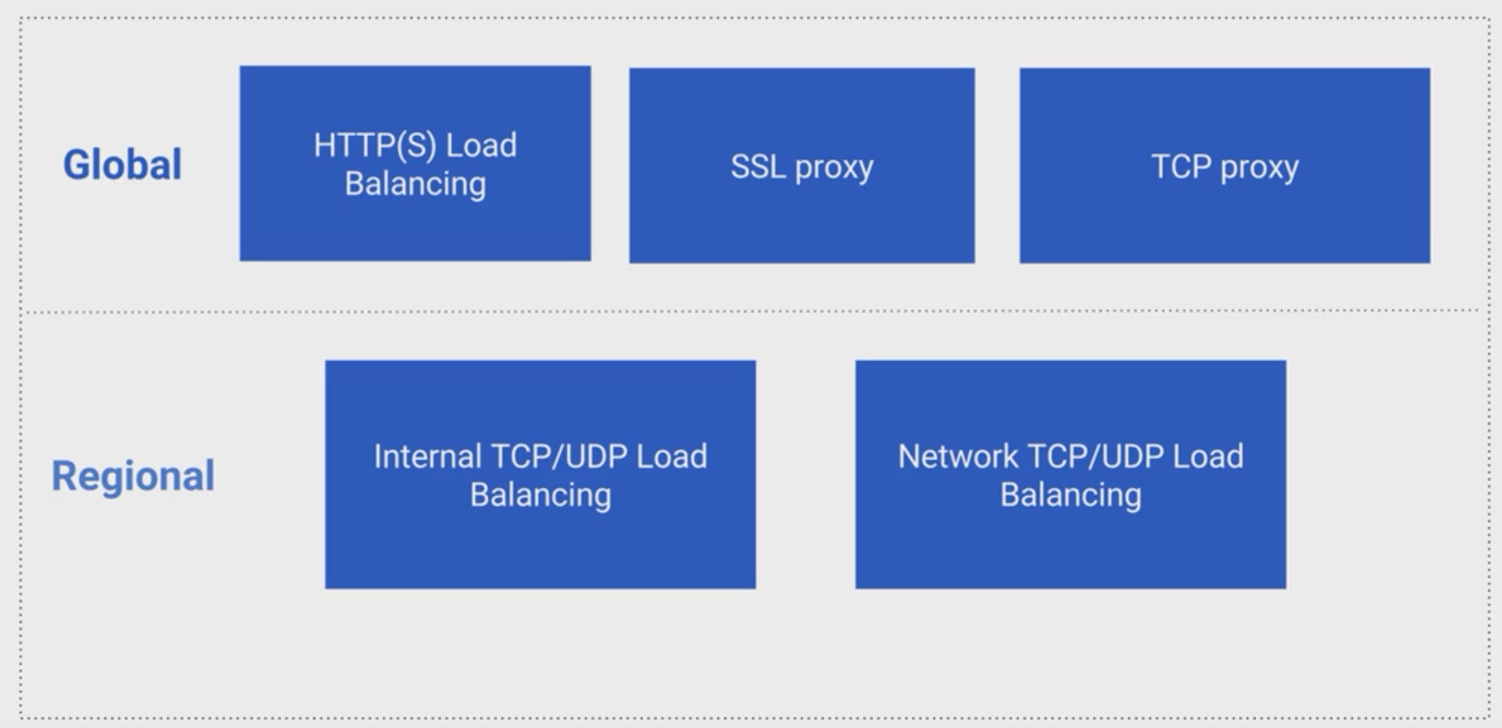
- Regional Network Load Balancer
- Supports:
- Session Affinity
- Setting up uses forwarding rules based on IP, protocol (TCP/UDP), and (optionally) port
- Round Robin
- Health Checks
- Session Affinity
- Supports:
- Global Load Balancer
- Supports:
- Multi-region failover for HTTP(S), SSL Proxy, and TCP Proxy
- Supports:
- Regional Network Load Balancer
*LB Types
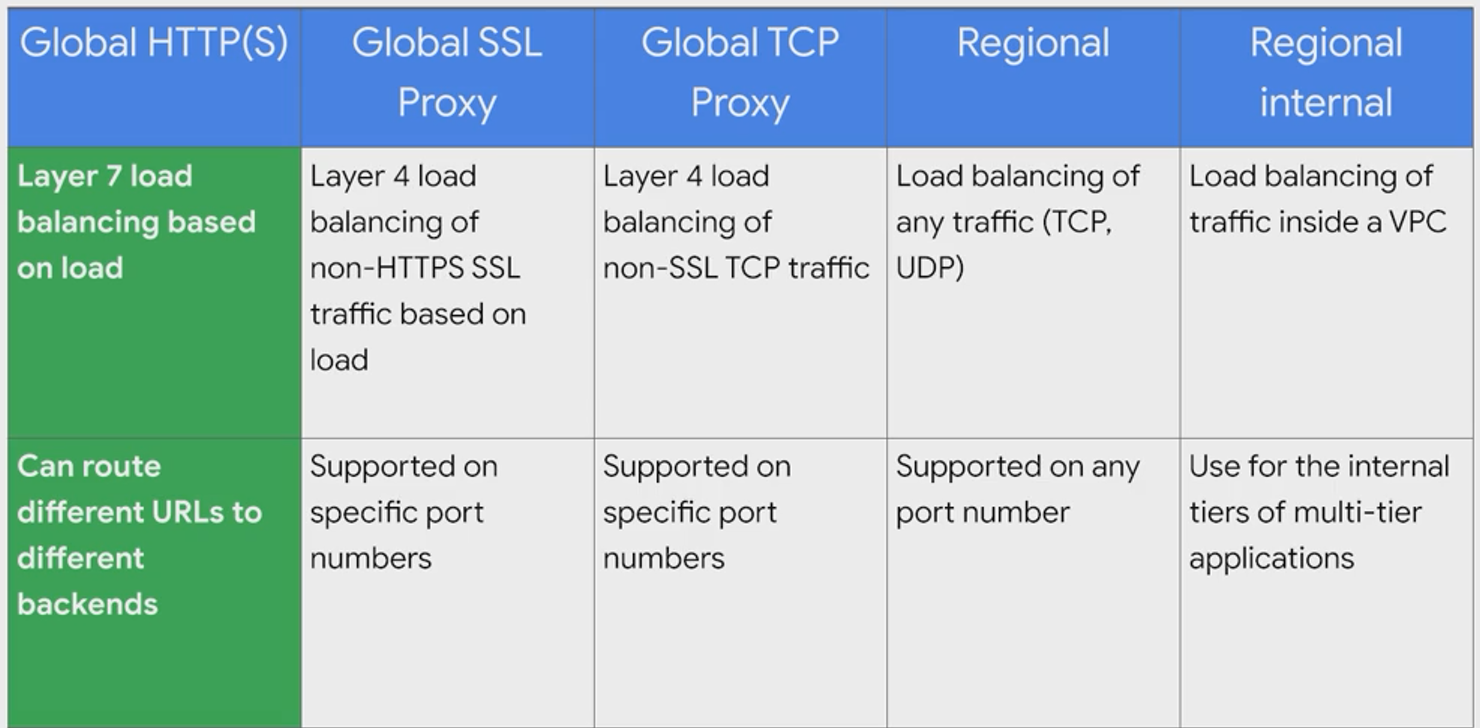
- Global HTTPS(S) Load Balancing
- HTTP LB
- HTTPS LB
- Internet facing or single and multi-region
- Global TCP Load Balancing
- TCP LB
- TCP Proxy
- Internet facing or single and multi-region
- Global SSL Proxy
- Regional
- Regional Internal
- Global HTTPS(S) Load Balancing
CDN
Cloud CDN
Range: Global
- Low-latency content delivery
- Based on HTTP(S) CLB & integrated with GCE & GCS
- Supports GCP only
- HTTP(S) LBs
- Backend can be a GCS Bucket
- Does not support custom origins
- HTTP(S) LBs
- Supports the following protocols of HTTP/2 and HTTPS
- Pay for
- POP to client network egress
- HTTP(S) request volume
- Per cache invalidation request (not per resource)
CND Interconnect
Range: Regional/Multi-Regional
- Direct, low-latency connectivity to certain CDN providers, with cheaper egress
- For external CDNs, not GCP’s CDN service
- Supports:
- Akami
- Cloudflare
- Fastly
- Contact CDN provider to set up for GCP project and which regions
- Free to enable, then pay less for the egress you configured
Connection
Cloud Interconnect (Not Physical Link)
Range: Regional/Multi-Regional
Use Case
Say you have an application running within GCP on a GCE instance but you need to let the application access data from a business system on-premise then you would choose to Cloud Interconnect
→ Connecting external networks to Google’s network
Direct access to RFC1918 IPs in your VPC - with SLA (Private Connections)
- Dedicated Interconnect
- Cloud VPN
Access to Google public IPs only - without SLA Peering
- Direct Peering
- Carrier Peering
Cloud VPN
Range: Regional
- IPsec VPN
- To connect to VPC via public internet for low-volume data connections
- Persistent, static connections between gateways
- Not for a Dynamic client
- VPN Gateways must have static IP
- Encrypted link to VPC, into one subnet
- Supports both Static and Dynamic routing
- Dynamic is preferred to stop the need to re-establish the connection
- 99.9% availability SLA
- Pay per tunnel-hour
- Normal traffic charges apply
Dedicated Interconnect
Range: Regional/Multi-Regional
- Direct physical link between VPC and on-prem for high-volume data connections
- VLAN attachment is private connection to VPC in one region; no public GCP APIs
- Link are private but not encrypted
- You need to layer your own encryption in order to achieve encrypted traffic
- Redundant connections are advised to provide high availabilty achieving 99.99% SLA.
- Without redundant conneciotns the SLA is 99.9%
- Pay fee per 10Gbps link, plus small fee per VLAN attachment
Cloud Router
Range: Regional
- Dynamic routing using BGP for hybrid networks linking GCP VPCs to external networks
- Works with Cloud VPN and Dedicated Interconnect
- Automatically learns subnets in VPC and announces them to on-prem network
- Without Cloud Router you must manage static routes for VPN
- Free to setup
- Pay for VPC egress
VPC
Range: Global
- Global IPv4 unicast SDN for GCP resources
- Subnets are Regional
- Can:
- Be shared across multiple Projects
- Be peered with other VPCs
- Enable private (internal IP) access to some GCP services (e.g. BQ, GCS)
- Pay for:
- Certain services (e.g. VPN)
- Network egress
Shared VPC
Shared VPC overview | Google Cloud
Shared VPC allows an organization to connect resources from multiple projects to a common Virtual Private Cloud (VPC) network, so that they can communicate with each other securely and efficiently using internal IPs from that network. When you use Shared VPC, you designate a project as a host project and attach one or more other service projects to it. The VPC networks in the host project are called Shared VPC networks. Eligible resources from service projects can use subnets in the Shared VPC network.
Compute
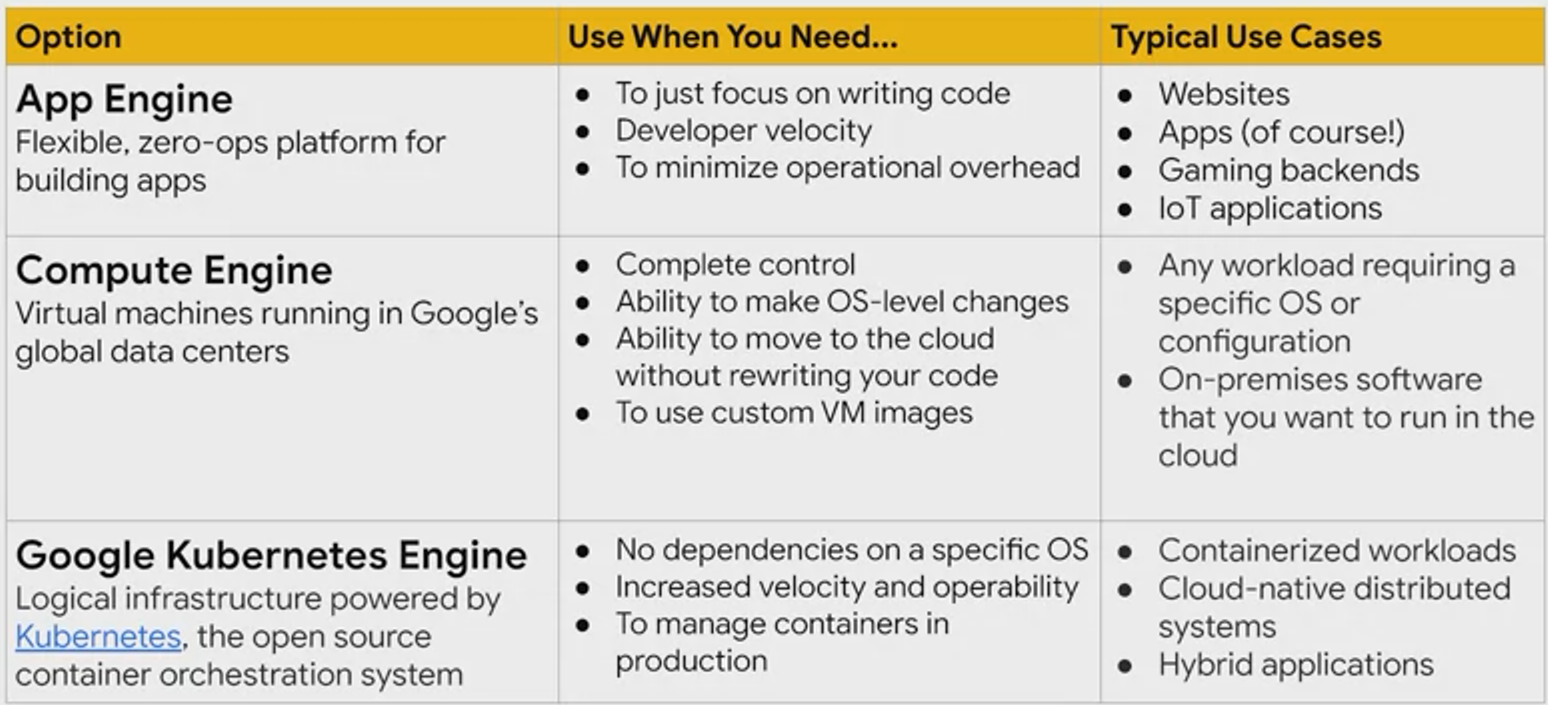
Google Compute Engine (GCE)
Range: Zonal
- IaaS
- VMs referred to as Instances
- Offers complete control and most flexibility at the cost of the following administrative burdens
- CPU/GPU
- Memory
- Disk Space
- OS
- Firewall Controls
- Network Connection/management (VPN/Load Balancing)
Instance Type
OS
Machine Type
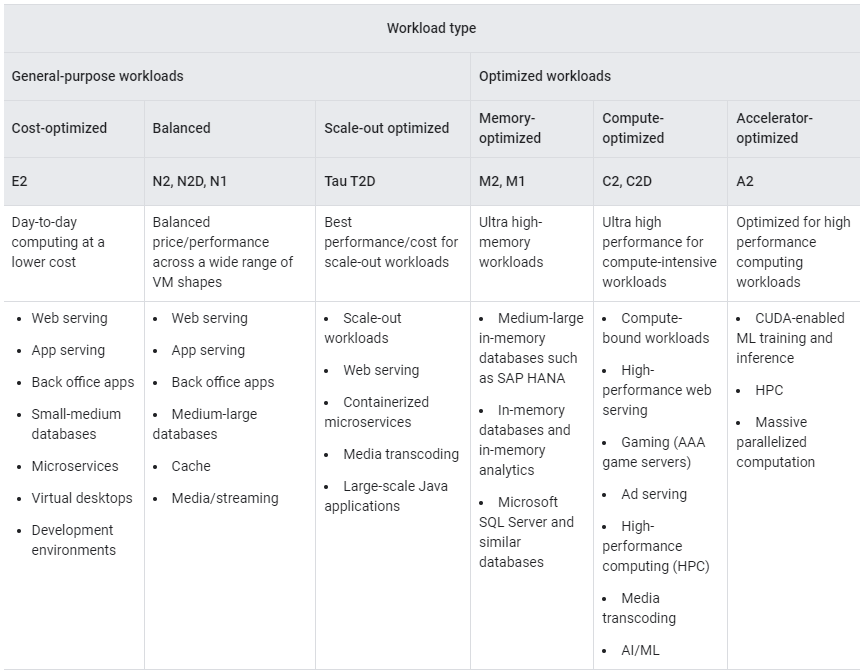
Spot & Preemptible VM
Spot/Preemptible VMs are available at much lower price—a 60-91% discount— compared to the price of standard VMs. However, Compute Engine might preempt Spot VMs if it needs to reclaim those resources for other tasks.
Custom Machine-Type VM
Compute Engine offers predefined machine types that you can use when you create a VM instance. A predefined machine type has a preset number of vCPUs and amount of memory, and is charged at a set price.
If predefined VMs don’t meet your needs, you can create a VM instance with custom virtualized hardware settings. Specifically, you can create a VM instance with a custom number of vCPUs and amount of memory, effectively using a custom machine type. Custom machine types are available in the general-purpose machine family. When you create a custom VM, you’re deploying a custom VM from the E2, N2, N2D, or N1 machine family.
HPC-ready VM
SQL Server VM
Instance Group
→ Like Auto-Scaling Group in AWS
You can create and manage groups of VM instances so that you don’t have to individually control each instance in your project. Compute Engine offers two different types of instance groups:
managed
Uses instance templates to create a group of identical resources. Making changes to instances will make the changes to the whole instance group, benefits of homongenous grouping of VM instances are:
(a) Automatic scaling; → resilient
(b) Work with Load Balancing to distribute traffic to all of the instances in the group; → distrbiuted
(c) If an instance in a group stops, crashes, or is deleted then the group automatically recreates the instance. → fault-tolerant
zonal managed instance groups
A Zonal managed instance group will contain instances from the same zone.
Note: Choose zonal if you want to avoid the slightly higher latency incurred by cross-zone communication or if you need fine-grained control of the sizes of your groups in each zone.
regional managed instance groups
A Regional group will contain instances from multiple zones across the region.
Note: This is general recommended group over Zonal as it protects against zonal failures and unforeseen scenarions where an entire group of instances in a single zone malfunctions.
unmanaged
Unmanaged groups are groups of dissimilar instances that you can arbitrarily add and remove from the group. Unmanaged instance groups do not offer autoscaline, rolling update support, or the use of instance templates.
Note: Use if you need to apply load balancing to your pre-existing configurations or to groups of dissimilar instances.
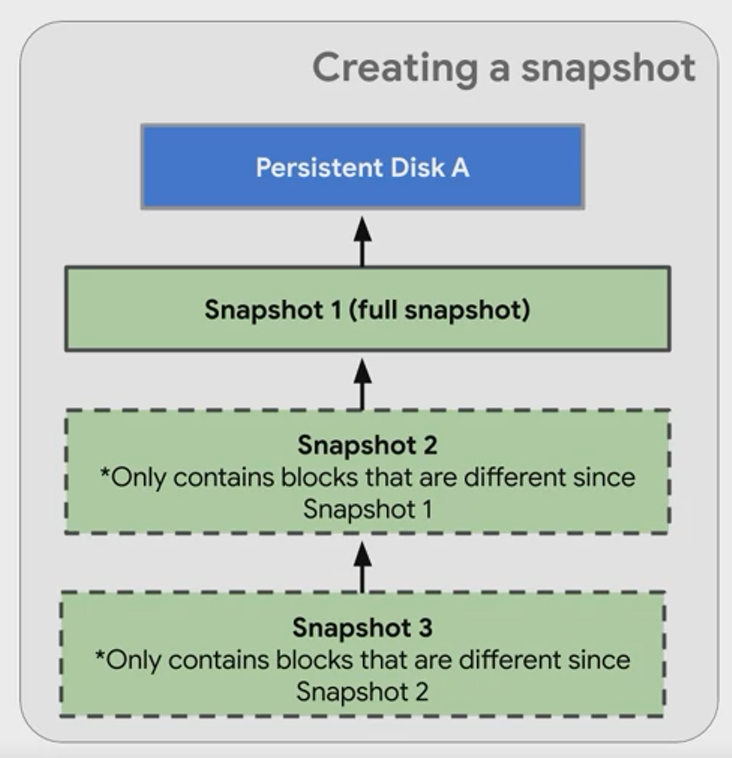
Snapshots
Public Image → provided and maintained by Google, both open source and third-party
Custom Image → only to your project
From different resources:
- A persistent disk
- A snapshot of a persistent disk
- Another image in your project
- An image that is shared from another project
- A compressed RAW image
Example: With Persistent Disk
Cloud Run
Develop and deploy highly scalable containerized applications on a fully managed serverless platform.
Google Kubernetes Engine (GKE)
Range: Regional
Managed Applications not machines
Powered by Kubernetes
Deploy containerized applications
De-couples app components from OS
Run app in multiple envs, regardless of OS
Kubernetes DNS on by default
No need for Consul unless wanted
No IAM integration
To connect with other GCP services you have top manage these secrets more manually.
Production clusters require ≥ 3 nodes
Integrates with Persistent Storage on underlying GCE components
*commands
# get pods
kubectl get podsGKE Sandbox
GKE Sandbox | Kubernetes Engine Documentation | Google Cloud
This page describes how GKE Sandbox protects the host kernel on your nodes when containers in the Pod execute unknown or untrusted code. For example, multi-tenant clusters such as software-as-a-service (SaaS) providers often execute unknown code submitted by their users.
GKE Sandbox uses gVisor, an open source project. This topic broadly discusses gVisor, but you can learn more details by reading the official gVisor documentation
App Engine
Range: Regional
- Managed Service
- No adminstration is needed for underlying infrastructure
- Deployment, maintenance, and scalability handled
- Developers can focus on writing the code, while Google handles the rest
- Build scalable web apps and mobile backends
Type
Standard
Supports: Python, Go, Java, PHP
Flexible
Supports: Java, Python, Node.js, .NET Core, Go, PHP, Ruby, etc.
Hierarchy
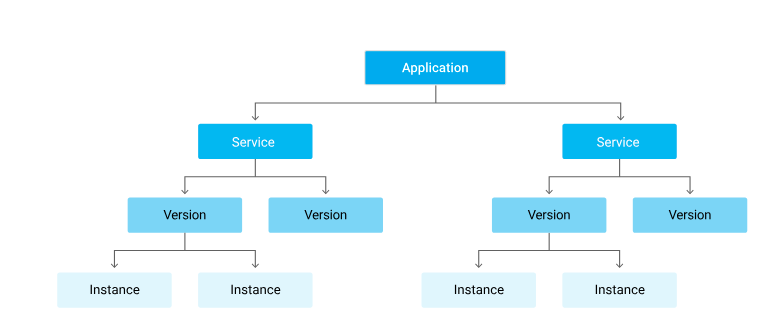
Scaling Options
Manual scaling → Resident Instances
A service with manual scaling use resident instances that continuously run the specified number of instances irrespective of the load level. This allows tasks such as compel initializations and applications that rely on the state of the memory over time.
Automatic scaling → Dynamic Instances
Auto scaling services use dynamic instances that get created based on request rate, response latencies, and other application metrics. However, if you specify a number of minimum idle instances, that specified number of instances run as resident instances while any additional instances are dynamic.
Basic Scaling → Dynamic Instances
A service with basic scaling use dynamic instances. Each instance is created when the application receives a request. The instance will be turned down when the app becomes idle. Basic scaling is ideal for work that is intermittent or driven by user activity.
Versions
Cloud Functions
→ Like AWS Lambda
Range: Regional
FaaS (Functions as a Service, I.e. Serverless)
Runs Node.js code in response to an event
Triggers can include:
- GCS Objects
- Pub/Sub Messages
- HTTP Request
Pay for CPU & RAM assigned to function per 100ms (mins. 100ms)
Massive scalability (horizontally)
Storage/Data

Local SSD
Range: Zonal
Data is encrypted at rest
375GB SSD attached to each server
Similar to the ephemeral disk on AWS
Data is lost whenever the instance shuts down
Data survives live migrations
Pay for GB-month provisioned
Persistent Disk
Range: Zonal
Persistent disks
Performance scales with wolume size
Performance is way below that of a Local SSD but is still fast.
Can resize while in use but will need file system update within VM
Max file size: 10TB
Pricing = Incremental storage difference * ($ * time)
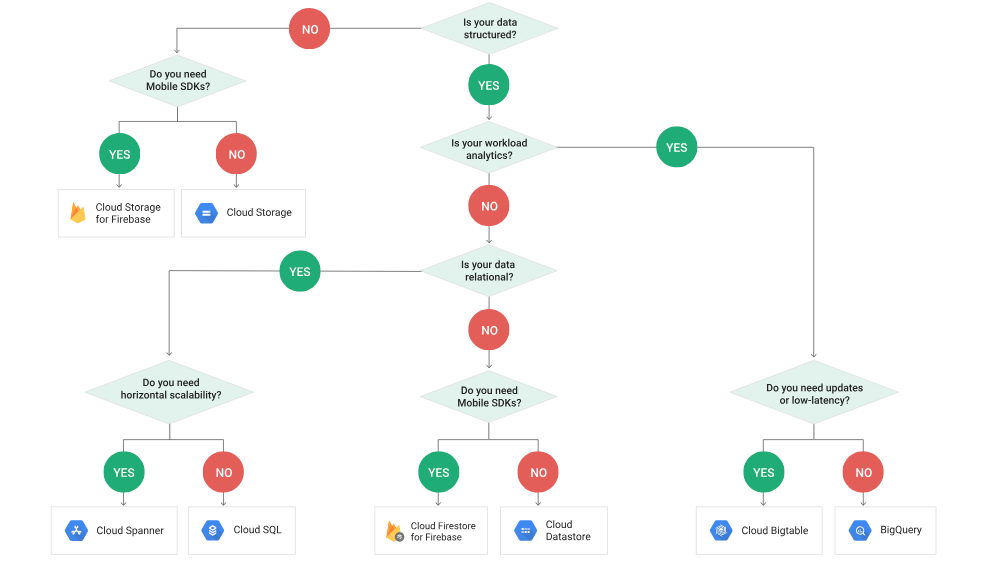
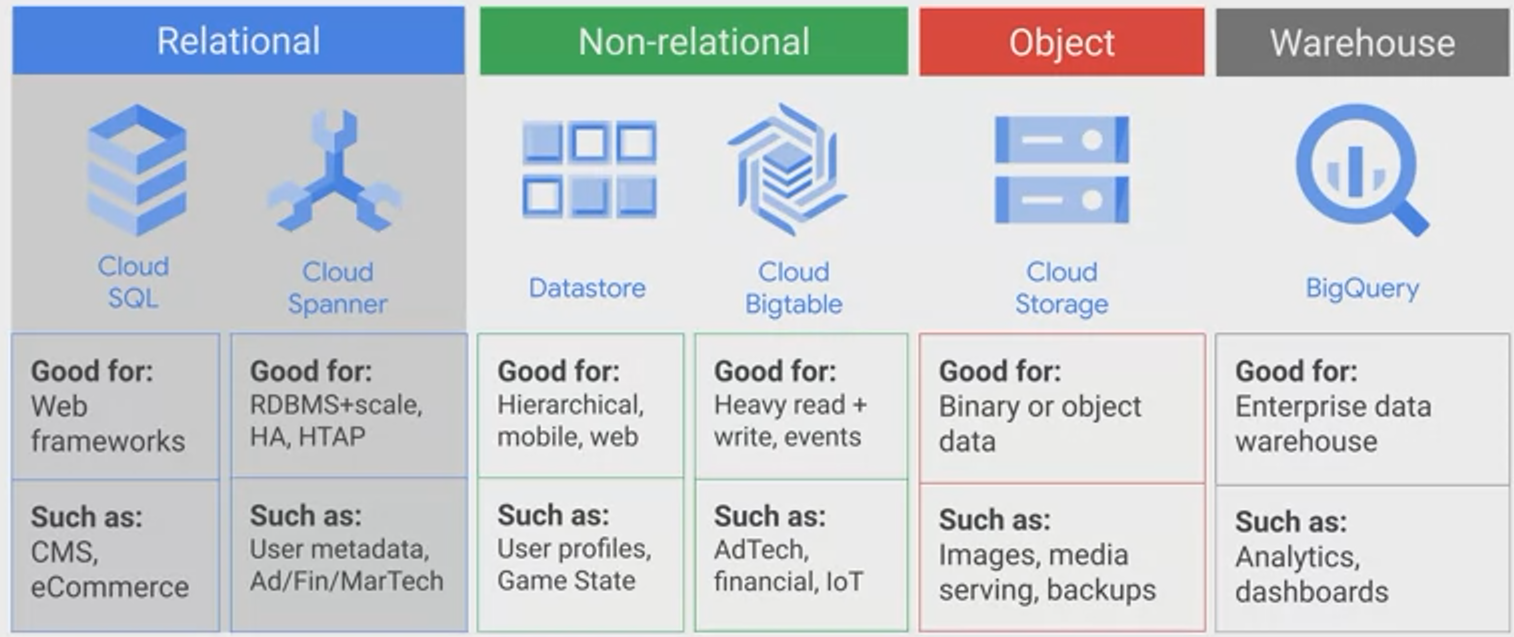
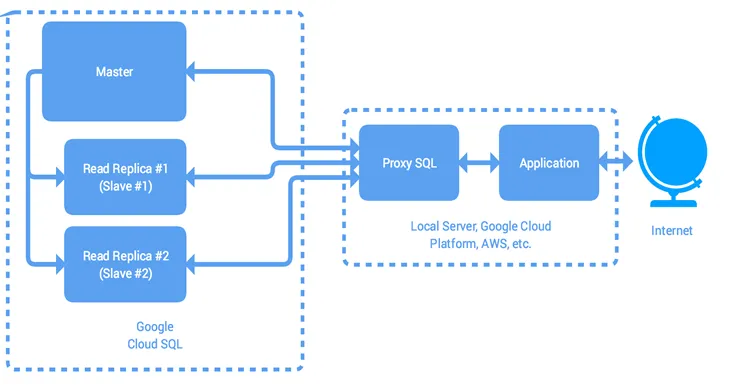
Cloud SQL
Range: Regional
- Fully Managed
- Databases:
- MySQL
- PostgreSQL
- SQL Server (new)
- Supports automatice replication, backup, failover
- Scaling is manual (both vertically and horizontally)
Cloud Spanner → NewSQL
Range: Regional / Multi-Regional / Global
Horizontally scalable
Strongly consistent
Provides external consistency which is far more than stongly
Relational database structure with non-relational horizontal scale
Supports SQL to query data
ACID transactions
Scales from 1 to thousands of nodes
Requires 3 nodes for a Production environment
Use only for large systems
Not for small apps/systems
Pay for provisioned node time (region/multi-region) and used storage time
Production systems are very costly
BigQuery → Data Warehouse
Range: Multi-Regional
BigQuery is Google’s serverless, highly scalable, low cost enterprise data warehouse designed to make all your data analysts productive. Because there is no infrastructure to manage, you can focus on analyzing data to find meaningful insights using familiar SQL and you don’t need a database administrator. BigQuery enables you to analyze all your data by creating a logical data warehouse over managed, columnar storage as well as data from object storage, and spreadsheets. BigQuery makes it easy to securely share insights within your organization and beyond as datasets, queries, spreadsheets and reports. BigQuery allows organizations to capture and analyze data in real-time using its powerful streaming ingestion capability so that your insights are always current. BigQuery is free for up to 1TB of data analyzed each month and 10GB of data stored.
- Serverless column-store data warehouse
- Supports SQL to query data
- Pay for:
- GBs actually considered (scanned) during queries
- Attempts to reuse cached results, which are free
- Data stored (GB-months)
- Relatively inexpensive
- This gets cheaper when tables are not modified for 90 days
- Streaming inserts paid per GB
- GBs actually considered (scanned) during queries
Estimate Cost of BigQuery
Estimate storage and query costs | BigQuery | Google Cloud
To estimate costs before running a query, you can use one of the following methods:
- Query validator in the Cloud Console
-dry_runflag in thebqcommand-line tooldryRunparameter when submitting a query job using the API- The Google Cloud Pricing Calculator
- Client libraries
Cloud Datastore → Document
Range: Regional / Multi-Regional
- Fully Managed
- NoSQL DB
- Similar to DynamoDB
- Capabilities:
- ACID transactions
- SQL-like queries
- Indexes
- RESTful interface
- Pay for GB-months of storage used
- Pay for IO operations (r, w, deletes) performed
Notes:
- Cloud Datastore was born as the structured data store for App Engine
- Scales from 0 to terabytes worth of data as your application grows
BigTable → KV
Cloud Storage (GCS) → Block
Range: Regional/Multi-Regional
- Fully Managed
- Strongly Consistent (for overwrite PUTs and DELETEs)
- Durability = 11 9’S
- Can provide site hosting functionality
- Lifecycle features
Type
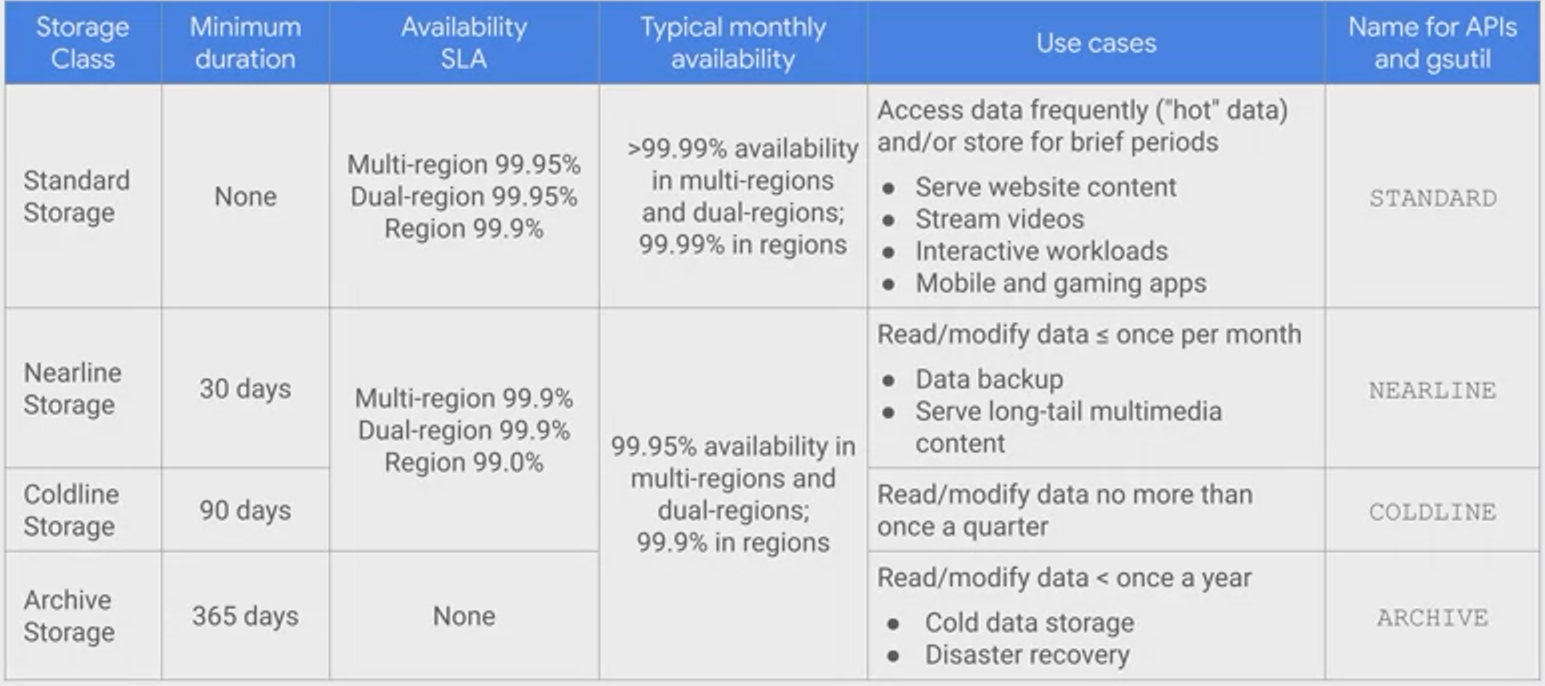
Nearline could be used for disaster backup
Standard
Regional
Storing frequently accessed in the same region as your Google Cloud DataProc or Google Compute Engine instances that use it, such as for data analytics.
- 99.99% typical monthly availability
- 99.9% availability SLA*
- Lower cost per GB stored
- Data stored in a narrow geographic region
- Redundant across availability zones
Multi-Regional
Storing data that is frequently accessed (“hot” objects) around the world, such as serving website content, streaming videos, or gaming and mobile applications.
99.99% typical monthly availability
- 99.95% availability SLA*
- Geo-redundant
Nearline
Data you do not expect to access frequently (i.e., no more than once per month). Ideal for back-up and serving long-tail multimedia content.
- 99.9% typical monthly availability
- 99.0% availability SLA*
- Very low cost per GB stored
- Data retrieval costs
- Higher per-operation costs
- 30-day minimum storage duration
Codeline
Data you expect to access infrequently (i.e., no more than once per year). Typically this is for disaster recovery, or data that is archived and may or may not be needed at some future time.
- 99.9% typical monthly availability
- 99.0% availability SLA*
- Lowest cost per GB stored
- Data retrieval costs
- Higher per-operation costs
- 90-day minimum storage duration
Archive
Life Cycle
Data Transfer
Transfer data from on-premise to GCP
Data Transfer Appliance → AWS Snowball
- Rackable, high-capacity storage server
- Physically transfer (ship) data from your data center to GCS
- Similar to AWS Snowball
- Ingest only
- 100 or 480TB versions
Storage Transfer Service
Range: Global
- If data is not in your own data center then you can use this
- Destination is always GCS bucket
- Source can be:
- S3
- HTTP/HTTPS endpoint
- GCS Bucket
- Pay for it’s actions, such as data transfer
Operation & Management
Cloud Identity
Range: Global
- Identity as a Service (IDaaS) to provision and manage users and groups
- Supports MFA and enforcement, including security keys
- Identities can be used to SSO with other apps via OIDC, SAML, OAuth2
- Can sync from AD and LDAP directories via Google Cloud Directory Sync
- Free Google Accounts for non Google Suite users, tied to a verified domain
Cloud Resource Management
Resource Manager documentation | Resource Manager Documentation | Google Cloud
Range: Global
- Hierarchically manage resources by project, folder, and organization
- Organization is root node in hierarchy
- Provides a Recycle bin which allows you to undelete projects
- You can define custom IAM roles at the organization level
- Can apply IAM policies at organization, folder or project levels
Cloud Operation (StackDriver)
Range: Global
- Multi-cloud monitoring and management service
- Integrated monitoring, logging and diagnostics
- Manages resources across platform
- Google Cloud
- AWS
- On-premises
- Provides observable signals on resource performance
Cloud Monitoring

Cloud Logging
- Stored for a limited number of days
- Length of storage varies:
- Admin Activity audit logs are kept for 400 days
- Data Access audit logs are kept for only 30 days
- You can export logs for analysis or longer storage
- Google Cloud’s Operations Suite Fundamental Quest : QwikLab 35
Cloud Deployment Manager
Range: Global
- Similar to Terraform and CloudFormation
- Create and Manage resources via declarative templates
- Templates written in:
- YAML
- Python
- Jinja2
- Supports input and output parameters
- Create and update of deployments both support preview
Billing
GCP Billing Operations
Billing Account
- To manage billing, you must be a billing admin
- To change a billing account, you must be:
- An owner on the project
- A billing admin on the billing account
- Projects are linked to billing accounts
- If you only have one account, all projects are linked to it
- If you don’t have billing account, you must create one to consume services
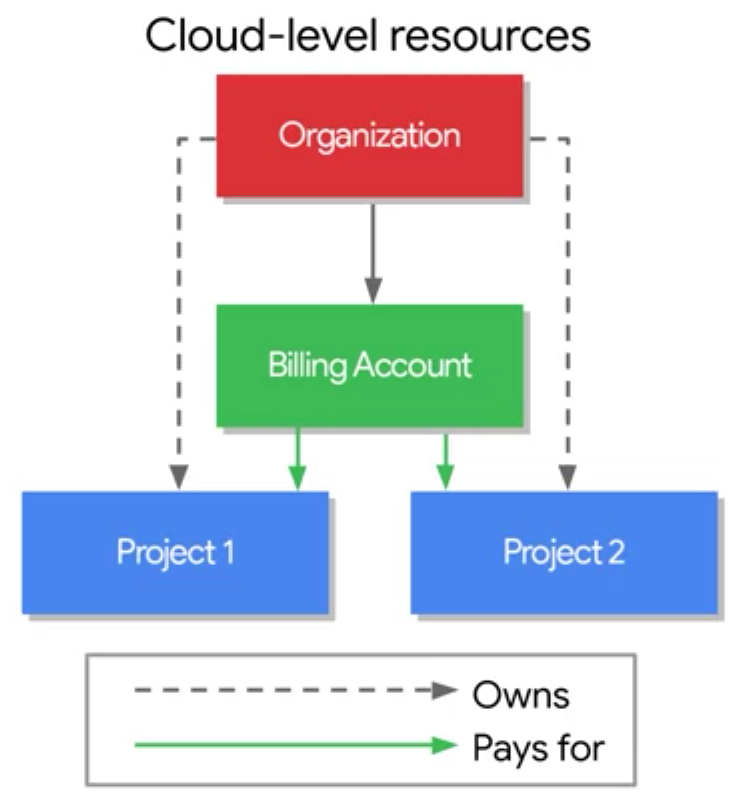
Budgets and Alerts
Alerts help prevent surprises on your bill
- To set a budget alert, you must be a billing admin
- You can apply budget alerts to either a billing account or a project
- You can set the budget to an amount you specify
- Setting a budget does not cap API usage
Cloud Billing API
Range: Global
Programmatically manage billing for GCP projects and get GCP pricing
Pricing Calculator
Estimate cost for daily, weekly, monthly, etc.
Big Data & IoT
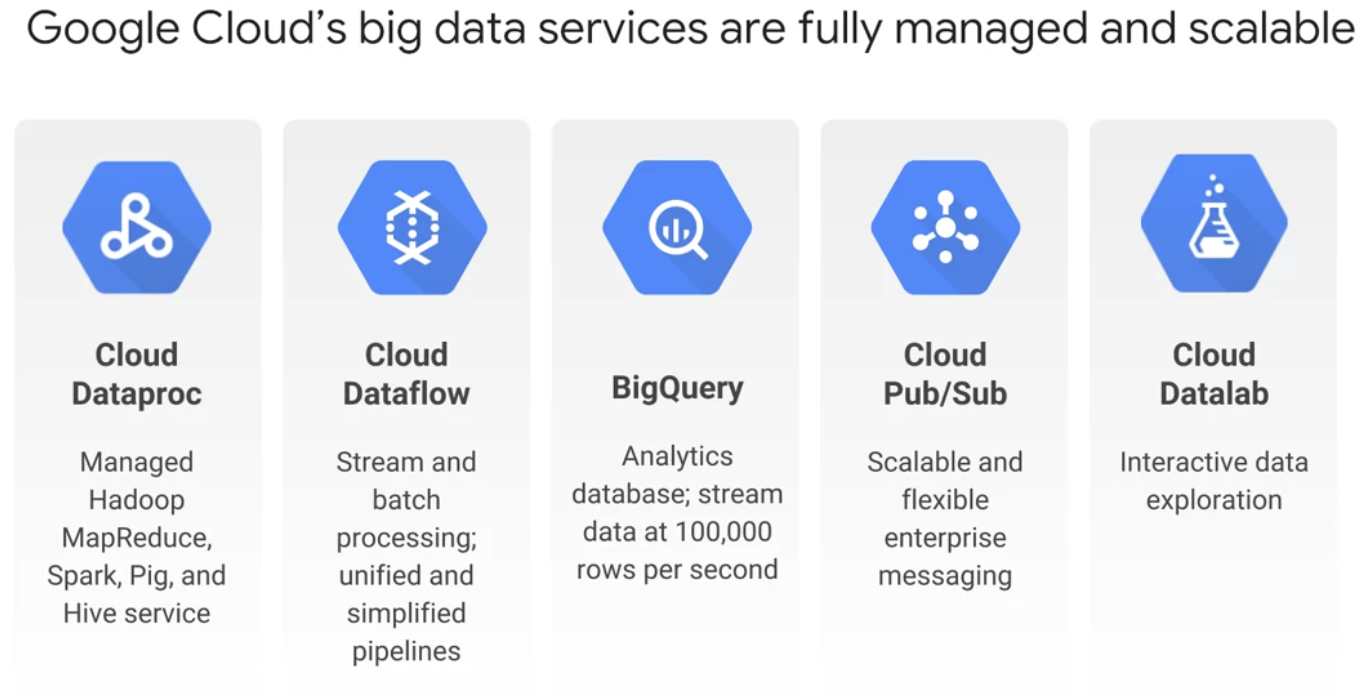
BigData Service

GCP Big Data Life Cycle
IoT Core
Range: Global
- Fully Managed
- A service to connect, manage, and ingest data from devices globally
- Devices connect securely using IoT industry-standard MQTT or HTTPS protocols
- CA signed certs can be used to verify device ownership on first connect
- Pay per MB of data exchanged with devices
Device Manager
- Handles device identity, authentication, config, and control
Protocol Bridge
- Publishes incoming telemetry to Cloud Pub/Sub for processing
Cloud Pub/Sub (Publish/Subscribe) → AWS SQS
Range: Global
- Infinitely scalable
- At least once messaging for ingestion, decoupling etc…
- Can be thought of as the “glue” that links everything together
- Pay for data volume; min 1KB per publish/push/pull request, not charged per message
- Can even end up being the replacement for things such as AWS Kinesis or Apache Kafka
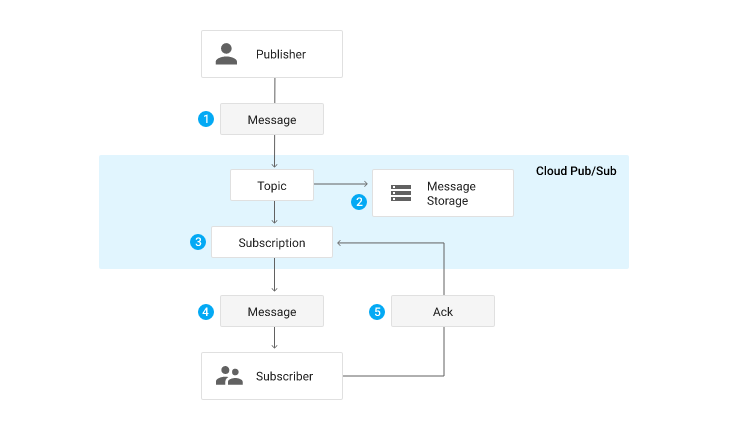
Components
- Topic and Subscribers
- A publisher sends a message to that topic which will then get sent to all the subscribers
Messages
- Can be up to 10MB
- Undelivered messages are stored for 7 days
- There is no DLQ (Dead Letter Queue)
Push
- Delivers to HTTPS endpoints
- Will delete messages when it receives an HTTP success code
- Uses a “slow-start” algorithm which ramps up on success and backs off & retries, on failures
Pull
- Delivers messages to requesting clients and waits for ACK to delete or until the timer expires
- Lets clients set rate of consumption, and supports batching and long-polling (Similar to AWS SQS)
Cloud Dataprep
Range: Global
- Visually explore, clean, and prep data for analysis without running servers (ETL)
- Ad-hoc ETL, for BA’s and not IT professionals
- Managed version of Trifacta Wrangler
- Source data can be from the services and types below, formatted in CSV, JSON, or relational:
- GCS
- BigQuery
- File Upload
- Automatically detects schemas, datatypes, possible joins, and various anomalies
- Pay for underlying Dataflow job, plus management overhead charge on top of the services accessed
Cloud Dataproc → MapReduce
Range: Zonal
- Batch MapReduce processing via configurable, managed Spark & Hadoop clusters
- Scales, by removing or adding nodes, even whhile jobs are running
- Integrates with:
- GCS
- BigQuery
- Bigtable
- Some Stackdriver services
- Pay for:
- underlying GCE servers used in the cluster
- a Cloud Dataproc management fee per vCPU-hour in the cluster
- You should use this service to move existing Spark/Hadoop setups to GCP
- You should use Cloud Dataflow for new data processing pipelines
Cloud Dataflow → Data Processing Pipeline
Range: Zonal
- Fully Managed Apache Beam
- Smartly-autoscaled and dynamically redistributes lagging work, mid-job, to optimize run time
- Batch or Stream MapReduce-like processing
- Integrates with:
- Cloud Pub/Sub
- Datastore,
- BigQuery
- Bigtable
- Cloud ML
- Stackdriver
- Pay for underlying worker GCE via consildated charges
- Pay per second for vCPUs, RAM GBs, and Persistent Disks
- Dataflow Shuffle charged for time per GB used
Cloud Datalab
- Interactive tool for data exploration, analysis, visualization and machine learning
- Uses Jupyter Notebook
Cloud Data Studio → Visualization
- Big Data Visualisation tool for dashboards and reporting
- Similiar to AWS Quicksight and Tableau
Other
10 Things Need to Know before Taking Exam
- Know gcloud commands for managing and creating objects such as gcloud projects list
- Know basic container terms. Pods, Deployment, etc. Also kubectl commands, such as
kubectl get pods - Know the use case and differences between Cloud Source Repo, Cloud Build and Container Registry
- Cloud SQL vs. Cloud Spanner, Big Table vs. Big Query, Cloud Datastire vs. Firebase (usecase, scaling)
- Know your use cases for data services, including Cloud Storage, App Enginem Kubernetes Engine, Cloud Pub/Sub, Cloud Dataflow
- Know how to deploy Window on compute engine (best way to login and authenticate) → secure
- IAM permissions basics. Know what service accounts are, know how to setup audit logs for auditors and logging best practices. Custom permission.
- Stackdriver (Cloud Operation) logging setup, setup alerts and difference between Stackdriver modules
- BigQuery pricing. Price calculator. Know on demand vs. flat rate. Storage pricing.
- How to save billing info but also query against.
Main Service
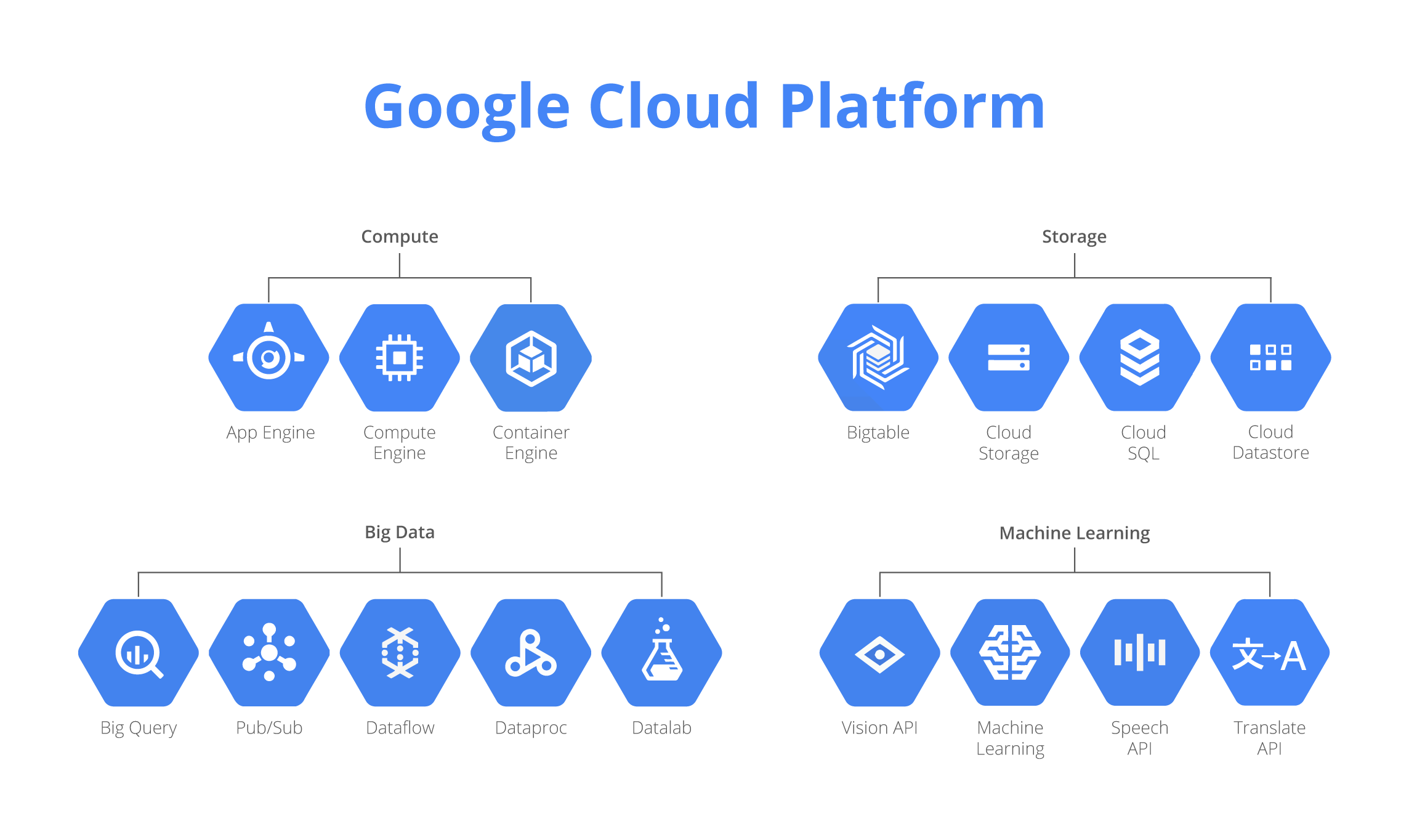
Resource Hierarchy
Organization → Folder → Project → Resource
*Project: control access to resources
Project Name: custom name
Project ID: global unique ID, cannot be changed after set
Project Number: GCP assigned id
Interacting with Google Cloud Platform
Google Cloud Platform Console
web user interface
Cloud Console Mobile App
For iOS and Android
REST-based API
For custom applications

API Explorer → interactive tool that lets you easily try Google APIs
- Google Client Libraries
- Google API Client Libraries
Cloud Shell
- Pre-configured Google SDK Linux Instance
- Automatic auth based upon GCP Console login
- Accessible via any web browser
- All client libs for web apps pre-installed
- 5GB persistent storage
Note: Direct/Interactive Use only
SDK & CLI
- Includes command-line tools for Cloud Platform products and services
gcloud,gsutil,bq
- Access via the Cloud Shell button in the Console
- Can also be installed on local machines
- Is also available as a Docker image
gcloud
Allows you to manage Google Cloud Platform resources and developer workflow
Format: gcloud [GROUP] [GROUP] [COMMAND] --arguments Example: gcloud compute instances create instance-1 --zone us-central1-a
Note
gcloud alpha...Feature is typically not ready for Production
gcloud beta...Feature on the other hand is normally a completed feature, that is being tested to be production ready.
gsutil → storage
bq → BigQuery
Basic Command Lines
# list project
gcloud projects list
# set your default project
gcloud config set project <project name>
# set defult region
gcloud config set compute/region "europe-west1"
# list compute regions
gcloud compute zone list
# describe a project
gcloud compute project-info describe <project name>Cloud Endpoints
Range: Global
- Handles auth, monitoring, logging, and API keys for APIs backed by GCP
- Based on NGINX and runs on a container (running on instances), called an ESP (Extensible Service Proxy) which is super fast and hook into the Cloud Load Balancer
- Uses JWT
- Integrates with:
- Firebase
- Auth0
- Google Auth
- Pay per call to your API